We introduce the Region Encoder Network (REN), a fast and effective model for generating
region-based image representations using point prompts. Recent methods combine class-agnostic
segmenters (e.g., SAM) with patch-based image encoders (e.g., DINO) to produce compact and
effective region representations, but they suffer from high computational cost due to the
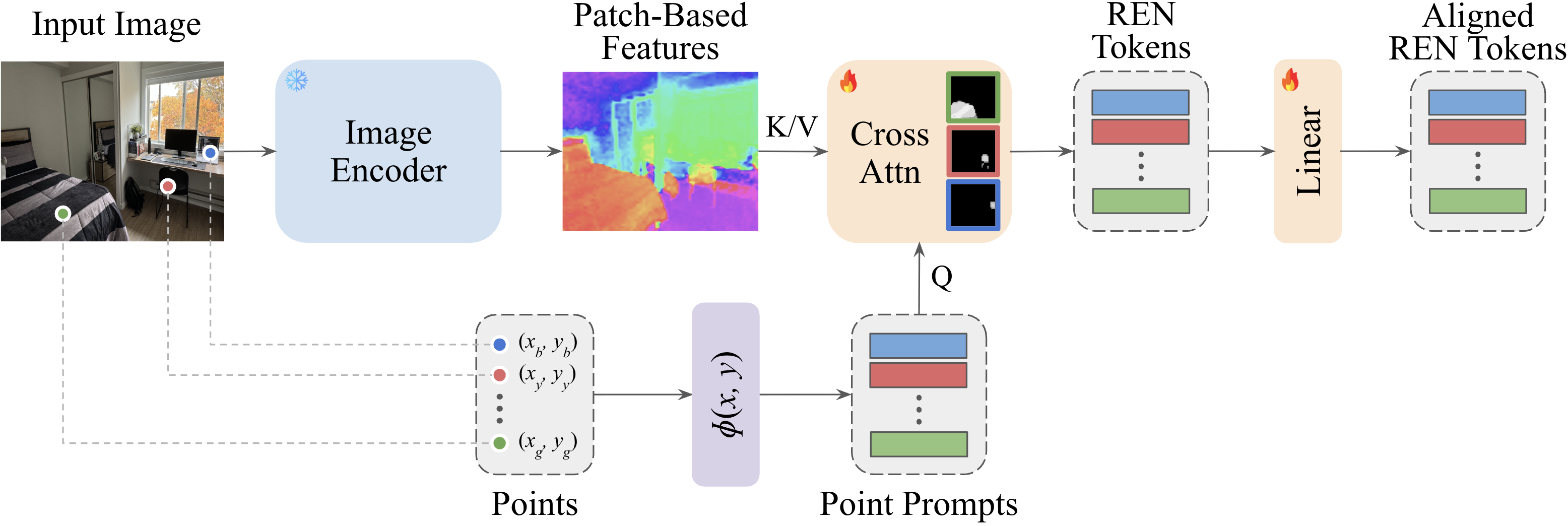
segmentation step. REN bypasses this bottleneck using a lightweight module that directly
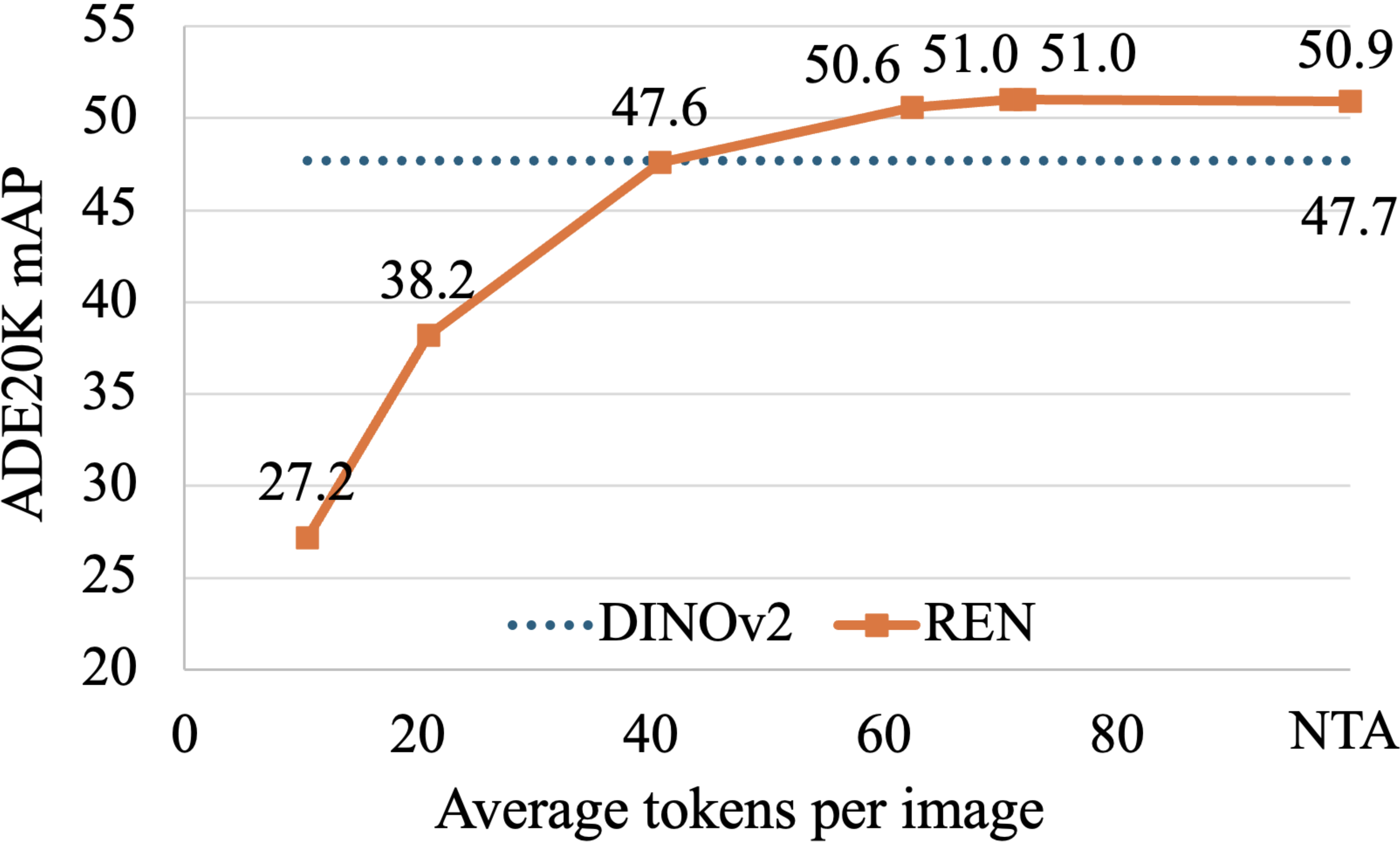
generates region tokens, enabling 60x faster token generation with 35x less memory,
while also improving token quality. It uses a few cross-attention blocks that take
point prompts as queries and features from a patch-based image encoder as keys and values to
produce region tokens that correspond to the prompted objects. We train REN with three popular
encoders—DINO, DINOv2, and OpenCLIP—and show that it can be extended to other encoders without
dedicated training. We evaluate REN on semantic segmentation and retrieval tasks, where it
consistently outperforms the original encoders in both performance and compactness, and matches
or exceeds SAM-based region methods while being significantly faster. Notably, REN achieves
state-of-the-art results on the challenging Ego4D VQ2D benchmark and outperforms proprietary
LMMs on Visual Haystacks' single-needle challenge.